![(please configure the [header_logo] section in trac.ini)](/mms/chrome/site/logomms.png)
Opened 15 years ago
Closed 15 years ago
#643 closed doubt (fixed)
Problemas con estimación y muchos parametros.
| Reported by: | fmunoz | Owned by: | vdebuen |
|---|---|---|---|
| Priority: | critical | Milestone: | Release 0.6 |
| Component: | Estimation | Keywords: | |
| Cc: | vdebuen@… |
Description
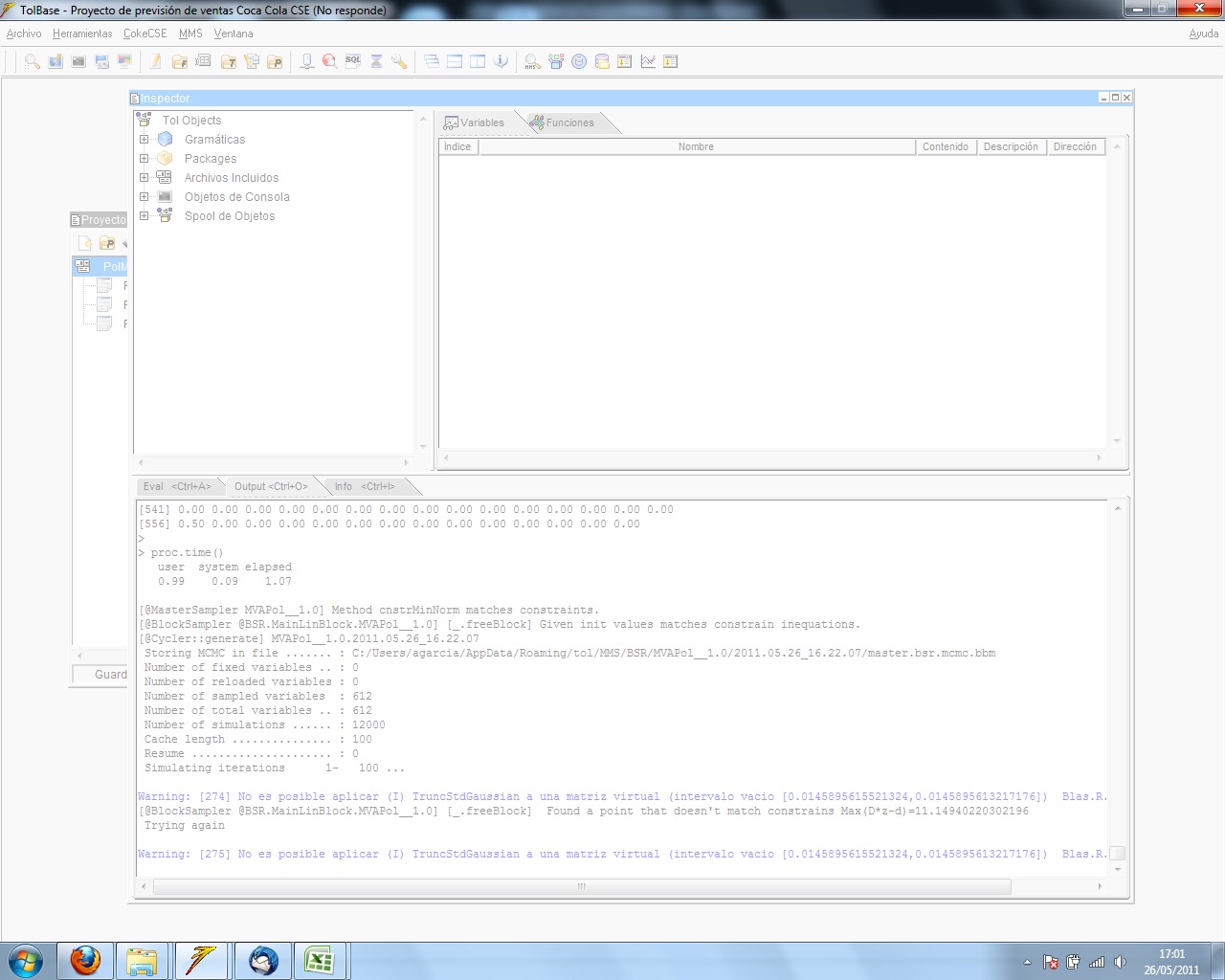
No conseguimos ejecutar la estimación adjunta. Tras iniciarse se queda bloqueada.
Hemos conprobado los valores iniciales y que cumplen las restricciones de dominio y todas las inecuaciones (model::CheckMCombinations.Constraint)
Tras depurar posibles problemas con series que tengan multicolinealidad (CheckMulticollinearity, manualmente y revisando las correlaciones entre las series 2 a 2) hemos conseguido comenzar la estimación pero se queda parada.
Idealmente, aparte de que nos echarais una mano en resolver esto, deberiamos de tener un conjunto de funciones auxiliares que ayudaran a buscar este tipo de problemas.
Attachments (1)
{kind=link}
{kind=link}
Change History (5)
Changed 15 years ago by
| Attachment: | tol_log.jpg added |
|---|
comment:1 Changed 15 years ago by
comment:2 Changed 15 years ago by
| Cc: | vdebuen@… added |
|---|
Yo no puedo acceder a esa ruta
nas02\entity\PrjCokCseMvaCse
En
nas02 sólo veo BDR, BMR, BPR
comment:3 Changed 15 years ago by
| Owner: | changed from Pedro Gea to vdebuen |
|---|---|
| Status: | new → accepted |
Ya lo he encontrado en
nas02\bdr\entity\PrjCokCseMvaCse
BSR tiene problemas para encontrar una solución factible y cuando lo hace no es capaz de avanzar hacia una zona de densidad razonable. Yo he conseguido encontrar una solución adecuada mediante un método que está aún en fase de pruebas y parece que consigue llegar a algo, pero la verdad es que el diseño del modelo me resulta a primera vista incompatible con el sentido común.
No me extraña en absoluto que tenga problemas en la estimación pues las dimensiones del modelo son demenciales a mi modo de ver:
- 569 variables
- 780 datos
- 585 ecuaciones a prior o latentes
- 2349 restrictiones
La superficie de contraste real es tan sólo 1.37 e incluso con los nodos prior y latentes no se llega más que a una superficie de contraste de 2.39. Lo ideal es tener una superficie de contraste en torno a 30 o más, aunque por encima de 10 ya empieza a ser creíble, y esto está lejísimos de ese mínimo. En cambio, a cada variable le tocan más de 4 restricciones.
A mí me resulta muy difícil creer en un modelo así. Sobran variables y restricciones y faltan ecuaciones. Si el modelo da más error pues da más error y punto. La realidad es tozuda y sobrecargar el modelo es engañarse a uno mismo.
Como no tengo ni idea del modelo sólo puedo dar consejos abstractos:
- Escalar las variables: Hay que elegir unidades adecuadas para cada input de manera que no haya variables que se midan en miles o millones y otras en milésimas o millonésimas, pues al operar grandes matrices mal escaladas se introduce mucho error de redondeo. En este caso no es extremadamente malo pero es bastante mejorable. Se podría integrar un sistema que lo haga internamente pero tampoco es tan sencillo y realmente cuesta muy poco pensar un poco antes de ponerse a definir inputs como un loco.
- Eliminar variables:
- identificando aquellas que no deberían ser muy distintas entre sí, o bien
- rediseñando el modelo para adecuarlo al conocimiento existente con una representación más parca.
- Añadir conocimiento a priori y/o latente:
- Siempre que se pueda es preferible una relación de tipo latente que un prior pues éste suele añadir más parámetros prefijados de forma más o menos arbitraria
- Un prior/latent nunca debe basarse en una mera intuición sino en conocimientos y razonamientos con una base sólida, y mejor si son irrebatibles.
- Cuando no se encuentran leyes aplicables pero hay evidencias o sospechas fundadas de que se debe cumplir cierta norma, entonces se debe ser prudente asignando las desviaciones típicas en el caso de prior normales, que son los que se admiten ahora mismo.
- Eliminar y/o corregir restricciones:
- Con una restricción fuera de lugar es suficiente para inutilizar un modelo y no hay forma de localizarlas de forma automática. Existen métodos nada triviales, en los que estoy trabajando, para detectar si el sistema da lugar a una región vacía, pero no es posible determinar cuál o cuales de las restricciones son las culpables. Cuando dos o más restricciones son incompatibles entre sí no es culpa de ninguna sino de todas.
- También puede ocurrir que el sistema de restricciones de lugar a una región no vacía pero que esté muy lejos del punto de máxima verosimilitud, en cuyo caso el simulador intentará acercarse a dicho punto topándose una y otra vez con la frontera de factibilidad. Según lo lejos que esté puede ser incapaz de generar la cadena, pero casi es peor que sea capaz de generarla y luego te creas los resultados cuando no tienen ningún sentido, pues las restricciones están contradiciendo los datos, y los datos son como los clientes de un negocio: los datos siempre tienen la razón. También estoy desarrollando métodos que nos avisen de esta situación.
- Las restricciones de signo y de orden suelen tener sentido, aunque con tanta variable es fácil liarse y hay que revisarlo bien.
- Quitar las acotaciones que no se basen en conocimientos reales porque no aportan nada. Por ejemplo, a mí me resulta difícil justificar que una variable tenga que estar entre 0.3345 y 2.416, que o sé si es el caso pero me lo encuentro mucho por ahí y nunca nadie me lo ha conseguido explicar de forma razonable. Si lo que tenemos es la convicción de que es imposible que la variable esté realmente fuera de ese intervalo por motivos demostrables, entonces hay que incluir la restricción. Por ejemplo, una variable que sea una proporción de una parte frente a un todo debe estar entre 0 y 1 sin lugar a dudas y así debe expresar. Pero si lo que tenemos es apenas una vaga idea, basada en la experiencia o en lo que sea, que nos hace pensar que una variable debería estar entre
aybcon una probabilidadp, entonces habría que expresarlo mediante un prior normal como éste:
Obsérvese que aunque un 99% da la sensación de ser un suceso casi seguro, si se genera un millón de muestras se obtienen valores cercanos a 1 y 10, relativamente alejados de los límites del intervalo.//Límite inferior del intervalo Real a = 3; //Límite superior Real b = 8; //Probabilidad de estar en el intervalo Real p = 0.99; //Número de sigmas de la normal correspondiente a p en un intervalo simétrico Real k = (-DistNormalInv((1-p)/2)); //Media del prior normal Real nu = (a+b)/2; //Desviación típica del prior normal Real sigma = (b-nu)/k; //A modo de ilustración y también para evitar confusiones es recomendable la //visualización gráfica del histograma de frecuencias de la normal Matrix freq = Frequency(Gaussian(100000,1,nu,sigma),100);
comment:4 Changed 15 years ago by
| Milestone: | → Release 0.6 |
|---|---|
| Resolution: | → fixed |
| sensitive: | → 0 |
| Status: | accepted → closed |
| Type: | defect → doubt |
| version: | → 0.6 |
Doy por cerrado el tique y lo catalogo como tique de duda por su contenido ilustrativo.
Si el problema persiste o aparece otro problema de esta naturaleza puede reabrirse este tique o crearse uno nuevo.
Adjunto zip de la carpeta de archivos BSR en
nas02\entity\PrjCokCseMvaCse\2011.05.26_16.52.38.zip